Belkasoft X 2.11: A Sneak Peek
Belkasoft X 2.11 is around the corner, and we cannot help but share the preview—this one is shaping up to be something special. BelkaGPT leads the charge with a suite of new capabilities built for the realities of modern casework—large data volumes, multilingual evidence, and the need for faster, more precise answers. Other areas of the product have seen meaningful updates too, with new and revamped acquisition methods and refined artifact support.

Topic detection in chats with BelkaGPT
Collect messages containing information of interest across all chats in the data source and review them under detected classes. The updated Belkasoft’s offline AI assistant, BelkaGPT, offers a number of useful predefined detectors that include money, drugs, operational coordination, and account access. More importantly—you can create and apply your own detectors.
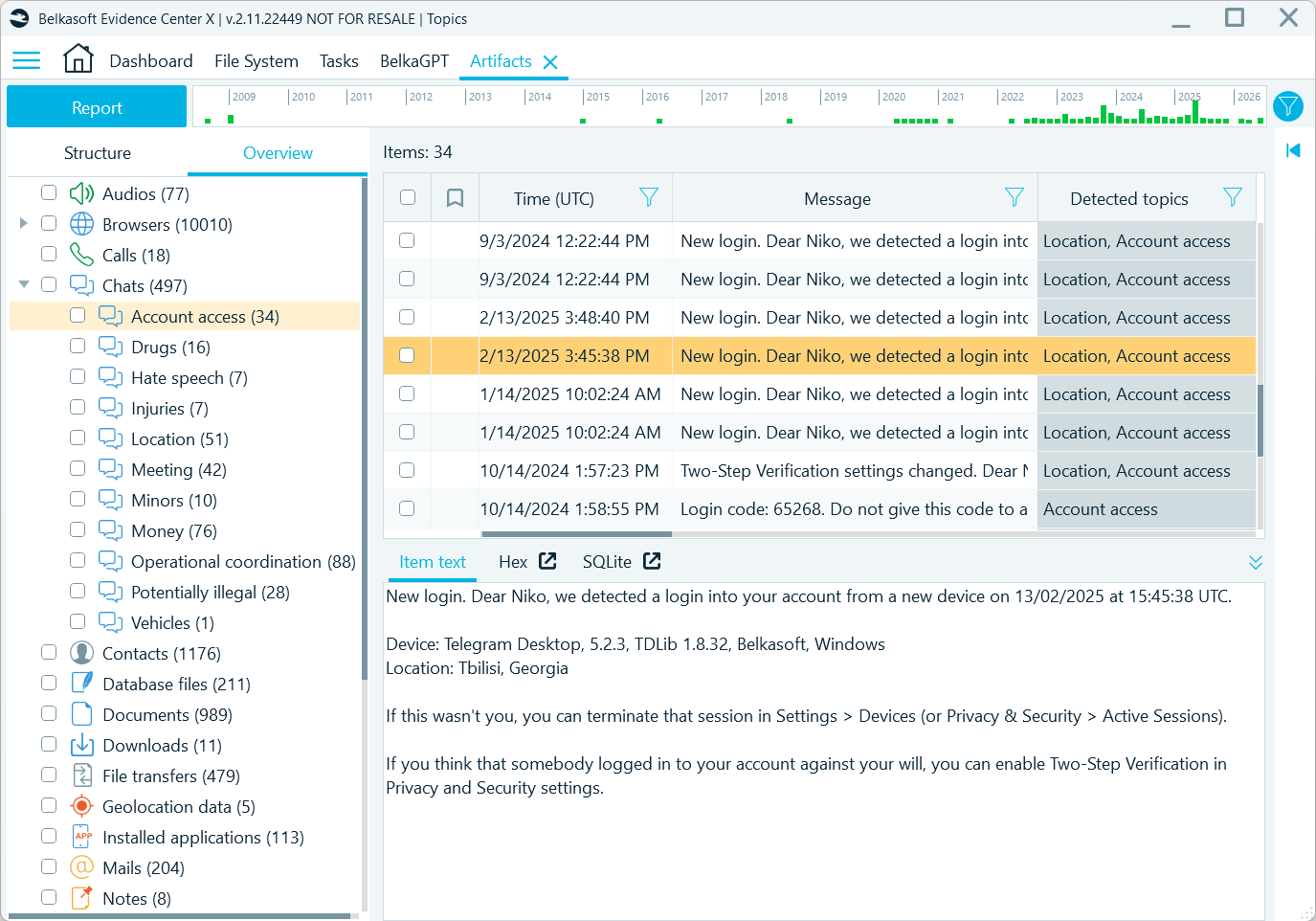
Belkasoft X displays detected topics in the Artifacts window and tags identified chats for filtering
With custom detectors, you can target exactly what matters in your case—whether that is coded language used within a criminal network, or, in corporate investigations, references to trade secrets and confidential information.
Since BelkaGPT topic detection is powered by a large language model rather than static keyword lists, it captures the full range of ways a subject can be expressed—slang, euphemisms, indirect references—so fewer relevant messages slip through the cracks.
That same AI foundation gives you another edge—the ability to track evidence in multiple languages. Imagine a case with chat data spanning Arabic, Spanish, and Vietnamese—instead of translating everything upfront, you can run a topic search across all of it, gauge how much relevant material exists in each language, and only then decide where translation resources are actually needed. Detection tends to be most precise for languages with similarities to English—Spanish and German, for example—though languages like Vietnamese also show strong results.
Unlimited artifact references in answers
When you ask BelkaGPT a question, it returns the most relevant artifacts alongside the answer, giving you direct access to the evidence behind it. Previously, that list was capped at 15 items. In 2.11, the cap will be gone: hit Show more below the answer to open an infinite scroll list of all matching artifacts, ranked by relevance score. This ability matters most for broad queries like "Show me all apps used" or "Find all drug-related mentions"—the kind where a 15-item limit could mean missing critical evidence.
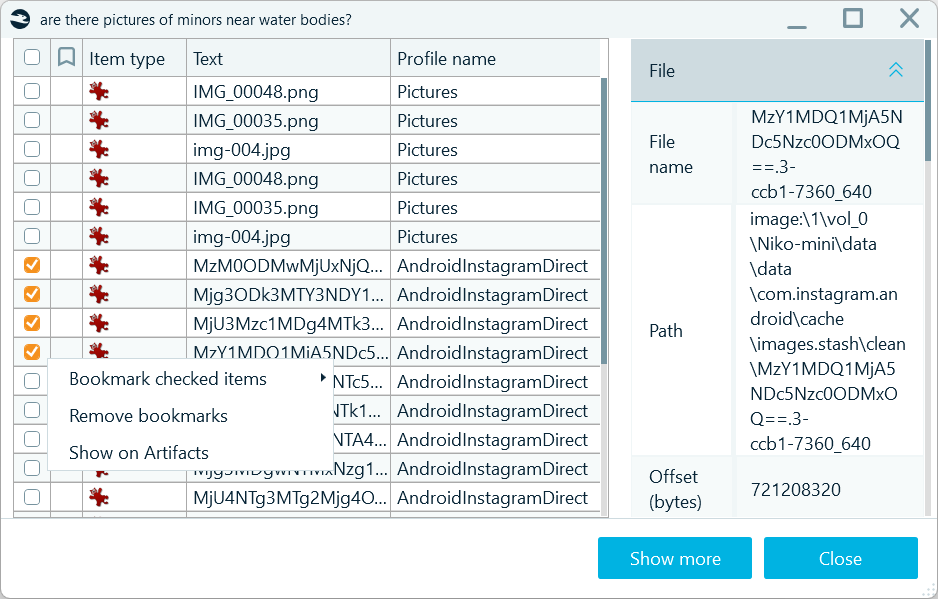
The Show more dialog also allows you to instantly access and bookmark found artifacts for efficient review and reporting
Extended support for natural-language time references
In addition to understanding date ranges introduced in previous versions, BelkaGPT Q&A can now accurately interpret questions referencing the earliest and latest events, making timeline queries more precise and reliable.
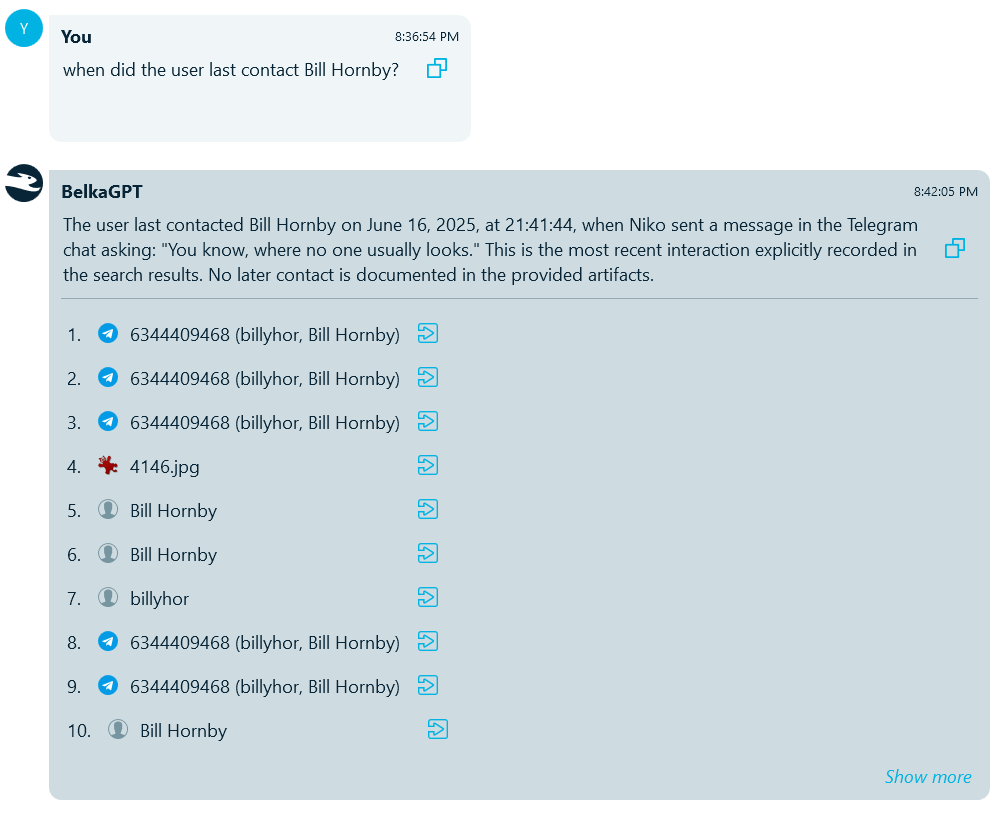
BelkaGPT can interpret queries including temporal references like "first," "last," "most recent," "last known" and guide its search accordingly
Automatic language detection
BelkaGPT now auto-detects the languages used in chats and documents, tagging them for search and filtering. It makes BelkaGPT Q&A significantly more accurate on language-specific queries, like "Find discussions about cars in French" or "Show me messages in Arabic mentioning investments."
Speech-to-text in BelkaGPT Hub
BelkaGPT Hub now supports converting speech from audio and video files to text, enabling faster, fully local processing without sending data to external services.
Other major improvements
These are just some of the new Belkasoft X highlights! As always, the release also includes new and updated artifact support, SQLite forensics improvements, enhanced Android location analysis, and a new Telegram cloud acquisition method—full details in the release notes very soon.