Document Forensics with Belkasoft X: Best Practices and Tips

Billions of files—text documents, slides, spreadsheets, and PDFs—are generated daily. These documents play a critical role in digital forensics by revealing evidence essential to criminal and corporate investigations.

In forensic investigations, digital documents can offer layers of information that go far beyond visible content. Investigators can unlock critical insights by carefully analyzing metadata, such as creation dates, modifications, and authorship, and examining embedded elements like images and links. This article covers best practices for analyzing text-searchable content, embedded media, and document metadata. Along the way, we also will demonstrate how Belkasoft X supports these practices:
- Metadata in documents
- Embedded media analysis
- Text-searchable content in document forensics
- Analyzing document metadata in Belkasoft X
- Working with embedded media
- Extracting media and enabling OCR in Belkasoft X
- Reviewing documents in Gallery view and Page previews
Read on to see how Belkasoft X brings efficiency to document forensics—from metadata and embedded media analysis to enhanced review processes and data extraction capabilities.
Document forensics: A deep dive into digital documents
It is easy to overlook key information within digital documents due to the sheer volume and density of textual evidence. However, with a thorough examination of metadata, embedded media, and text-searchable content, forensic analysts can uncover essential evidence and reconstruct digital timelines accurately.
Metadata in documents
Metadata, or "data about data", offers information about document origins, creation, modification, and access. Metadata can come from both the file system and be part of a file. You can use this information to reconstruct document history and trace usage to some degree.
File system metadata typically includes timestamps that indicate key moments in a document's lifecycle:
- Creation timestamp: Marks when the document was first saved on a storage medium, which may differ from its original authorship date.
- Modification timestamp: Records the last time the content of the document was altered.
- Access timestamp: Shows the last time the document was opened or interacted with.
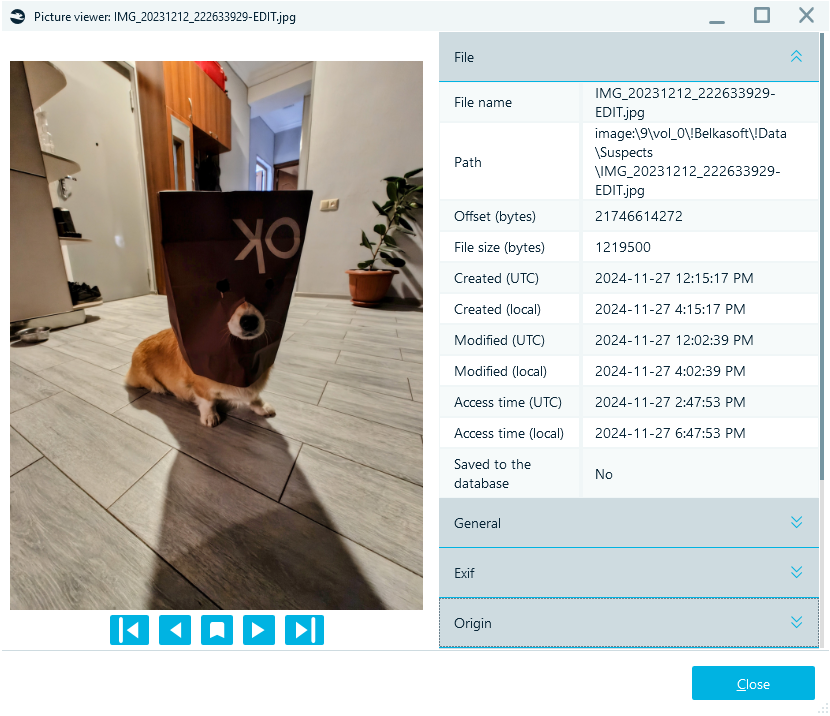
File metadata in Windows image properties
In addition to file system metadata, documents and embedded media may contain format-specific metadata such as:
- Author: The individual who created the document.
- Application: The software used to create or edit the document.
- Custom Data: Additional information specific to the file format, like EXIF data for images, can include geotags, camera settings, and other details.
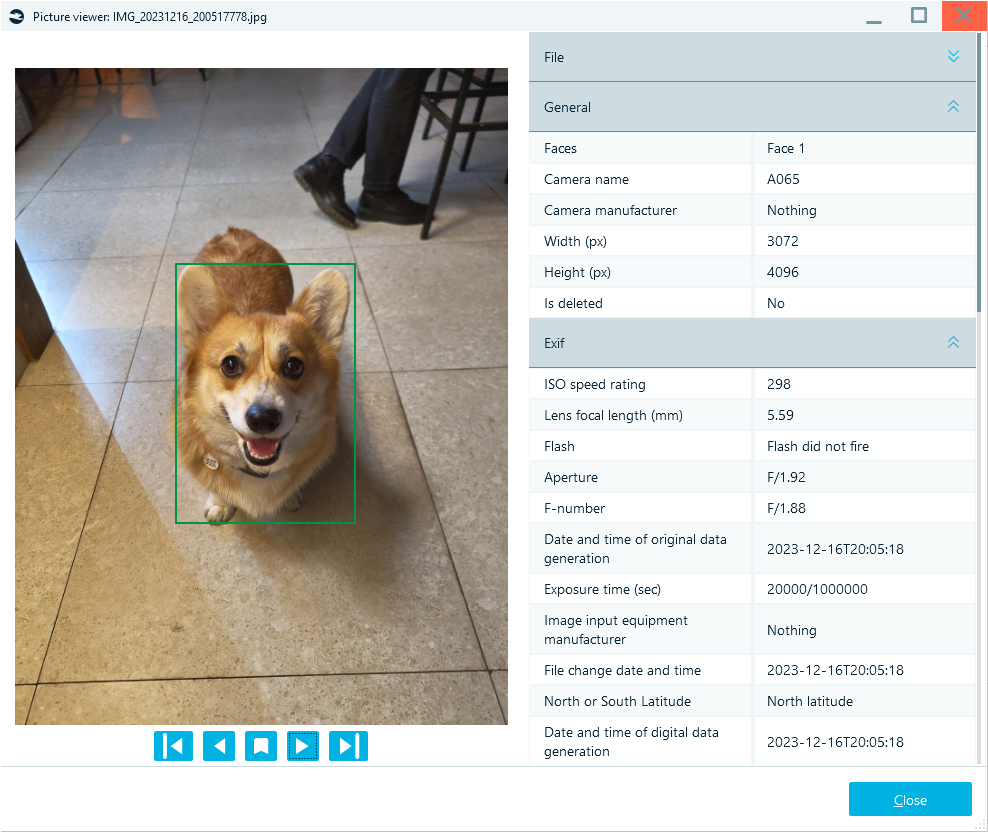
EXIF data in image properties
Forensic investigators can leverage metadata to:
- Reconstruct document history: By analyzing and correlating file system and file-specific timestamps, they can determine when a document was created, modified, or accessed, helping to establish its origin and history.
- Track usage: Access timestamps, whether embedded within the document or recorded by the file system, can indicate when the document was last opened or interacted with. While access metadata may not always provide specific user details, corroborating with other data sources (like user logs or network activity) can help reveal when a document was reviewed or compromised.
Document metadata reveals details on authorship, editing, and usage patterns that can help investigators reconstruct a document's history, detect tampering, and link to user activity.
Be aware that metadata can be tampered with and, in the case of file-specific metadata, entirely wiped, requiring you to examine other related artifacts to verify authenticity and uncover additional evidence. An example of such corroborative evidence is the presence of LNK files stored in the %AppData%\Microsoft\Windows\Recent folder.
Embedded media analysis
Documents may contain pictures and other multimedia files (for example, audio and video in presentations), which may reveal additional information if detached and analyzed separately. For instance, if illegal images are embedded in PDFs, proper analysis can prevent oversight. Media that has been extracted enables:
- Contextual evidence gathering: Visual elements such as diagrams or screenshots may contain critical clues.
- Metadata analysis: Images often carry EXIF metadata, including timestamps or geolocation, which is helpful for reconstructing timelines.
- Evidence verification: Comparing media elements with accompanying text provides a more comprehensive case understanding.
Embedded media should be thoroughly examined to help investigators uncover evidence that might otherwise go unnoticed.
Text-searchable content in document forensics
On top of the sheer amount of data in documents, one of the key challenges in digital document forensics is handling non-text-searchable content. Documents often include screenshots or images with text, requiring Optical Character Recognition (OCR) to make them searchable. Digital forensics tools like Belkasoft X provide OCR functionality that simplifies forensic document analysis. Having text in documents recognized and searchable can accelerate your investigation, as searchable content eliminates the need to sift through all documents, saving time.
How Belkasoft X facilitates document forensics
Belkasoft X provides a robust toolkit for analyzing digital documents. It automates metadata extraction, media analysis, and text recognition, helping you uncover critical evidence quickly and efficiently.
Analyzing document metadata in Belkasoft X
After data source processing, the user can review document metadata either in the Grid view or the Properties pane:
- File system metadata, which provides insights into when the document was created, last modified, or accessed, is visible under the File header.
- File-specific metadata, including author, application used, and other custom fields, can also be found under the Metadata header.
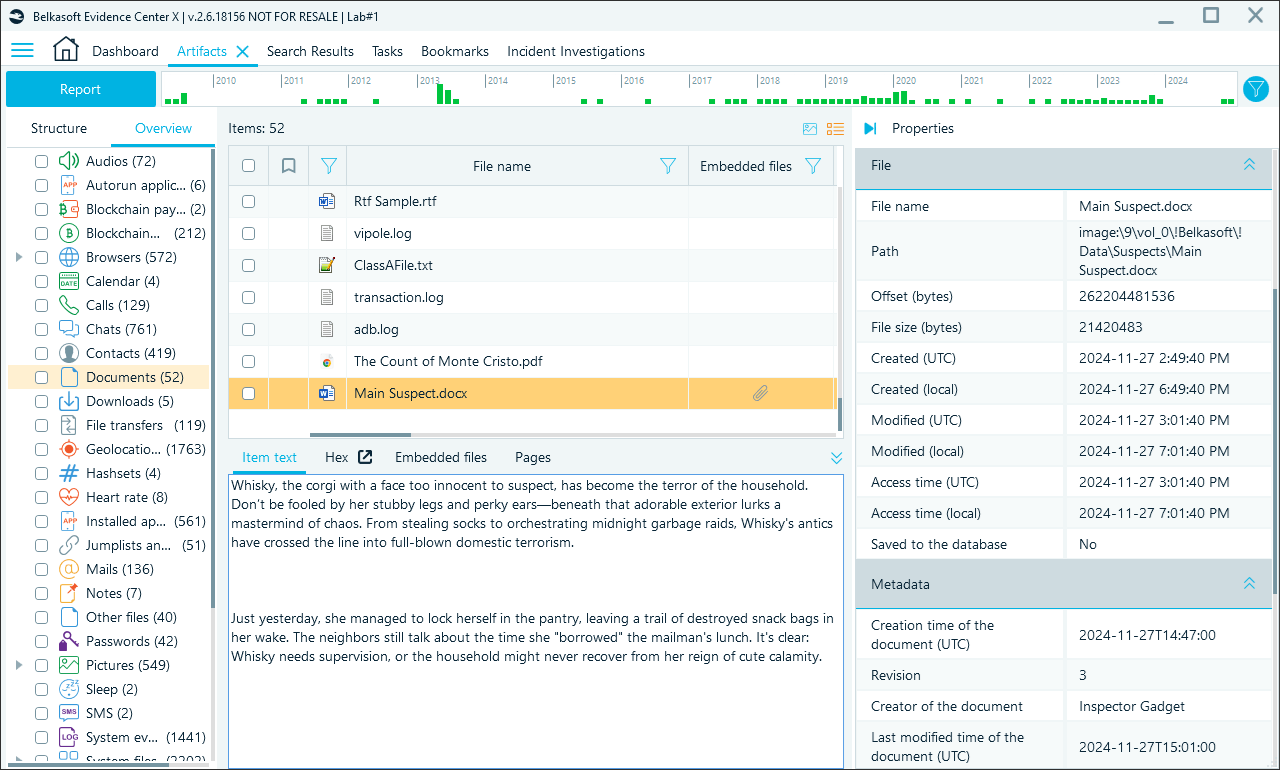
Metadata for .doc files in the properties section in Belkasoft X
Discrepancies in metadata can signal abnormal file operations or even tampering. For example, if the file's creation date in its metadata is earlier than the creation timestamp in the file system, it may indicate that the file was copied. Similarly, suppose the modification date in the metadata shows changes after the last modification date in the file system. In that case, it may suggest that the file was edited on another device—or that the timestamps were manually altered. Both scenarios should prompt further investigation, such as examining other metadata fields or corroborating with external evidence.
Thus, metadata can be a powerful tool in forensic investigations. Using Belkasoft X, you can easily review document metadata in the grid view or by checking the artifact properties. This approach allows you to examine timestamps and other relevant metadata elements thoroughly.
Working with embedded media
To properly analyze images and videos embedded within documents, extracting and examining them independently is essential. This process typically involves:
- Extraction of embedded media: Belkasoft X retrieves images, audio, or video embedded within files like PDFs, Word documents, or PowerPoint slide decks.
- Content analysis: You can turn on OCR for text within images, enabling keyword searches across visual content. OCR is beneficial when images contain screenshots of text conversations, receipts, or other documents. You can also run AI-powered picture categorization to pinpoint pictures with certain content faster. Currently, Belkasoft X can recognize text in more than 50 languages.
- Metadata analysis: Once extracted, media files can reveal "hidden" details, like geotags, timestamps, or information on the camera or device that captured the image or video.
Using these techniques, you can acquire a more comprehensive knowledge of the data inside documents, thus improving the effectiveness and accuracy of your investigations. You can cross-reference extracted media with other data sources or run a hashset analysis to identify whether images have been used elsewhere or altered.
Extracting media and enabling OCR in Belkasoft X
Belkasoft X can extract media files from documents and recognize text in them out of the box. You can enable these options during a data source import.
First, in the Select advanced analysis options window on the Artifacts tab, enable the Documentsartifact type, and then select the Analyze carved and embedded data option to extract media files embedded in documents.
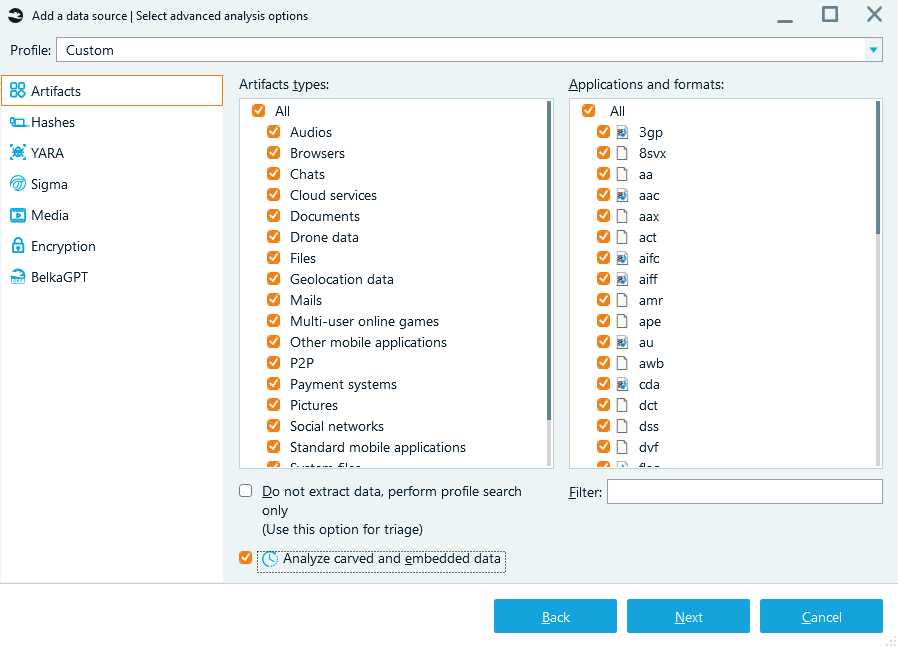
Enabling carved and embedded data analysis in Belkasoft X
Further on, media files can be categorized to support faster identification of relevant items. Belkasoft X supports the detection of specific content types within images and video key frames, including skin tone, pornography, faces, and guns. You can enable image classification and extraction of key frames in the Media tab.
To enable OCR for images and extracted media, select the Text checkbox and, from the drop-down below, select the recognition language. Text on pictures will be recognized, indexed, and will become searchable.
Note that enabling these options will increase processing time.
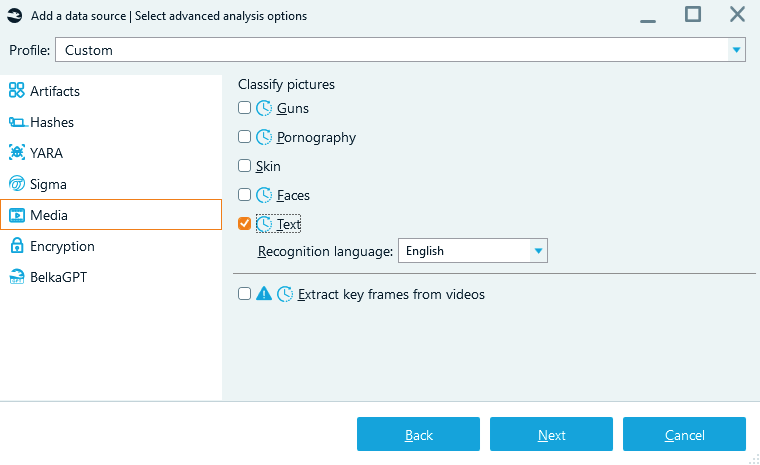
Enabling OCR during data source import in Belkasoft X
When you analyze a data source with these options enabled, Belkasoft X extracts all embedded media files, their metadata and runs additional analysis, such as picture classification or video keyframe extraction. The tool displays these files under the corresponding nodes (Pictures, Audio, Videos) in the Artifacts window. When viewing a document that includes media files, you will find them in the toolbar under the Embedded files tab.
Note that even if you do not enable embedded data analysis, Belkasoft X will still display extracted files under specific artifact categories and in the toolbar, but it will not extract their metadata or apply additional analysis options to the files.
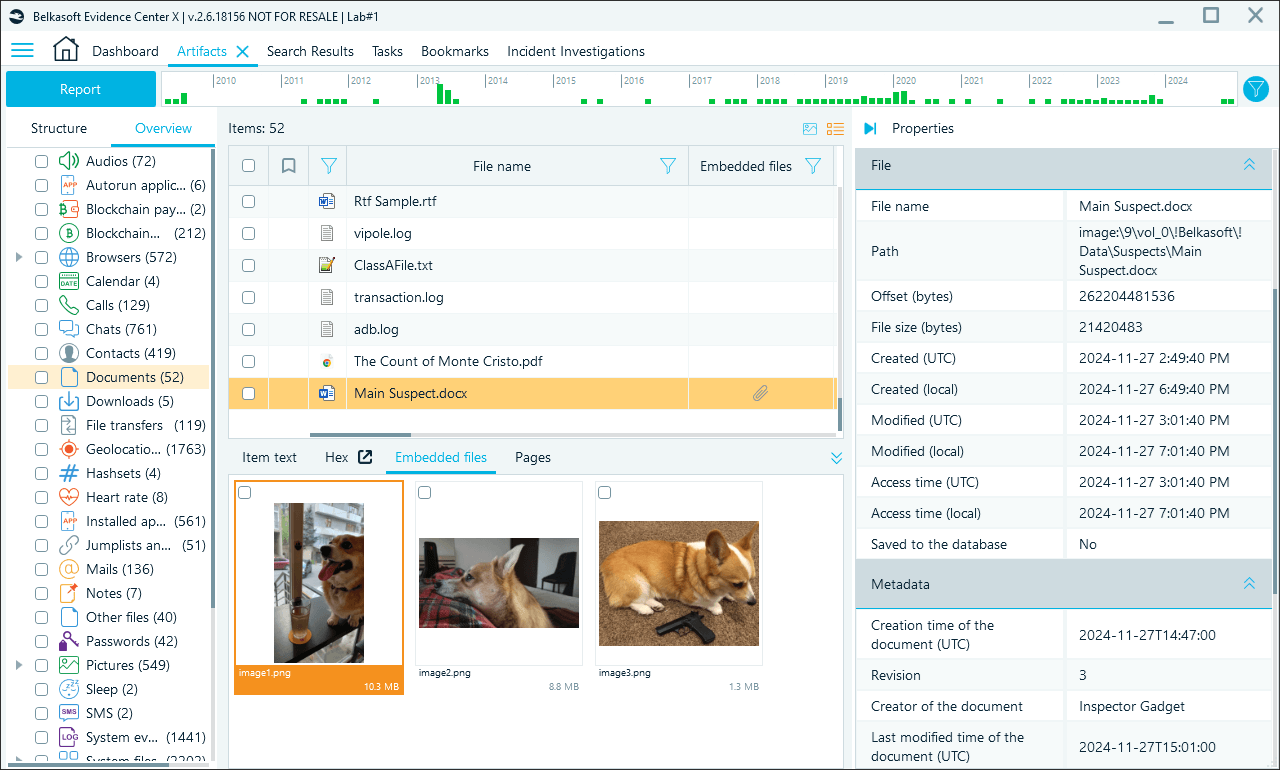
Embedded file preview in Belkasoft X
If you have enabled embedded media analysis and text recognition on images, your searches will now include the text extracted from embedded media as well:
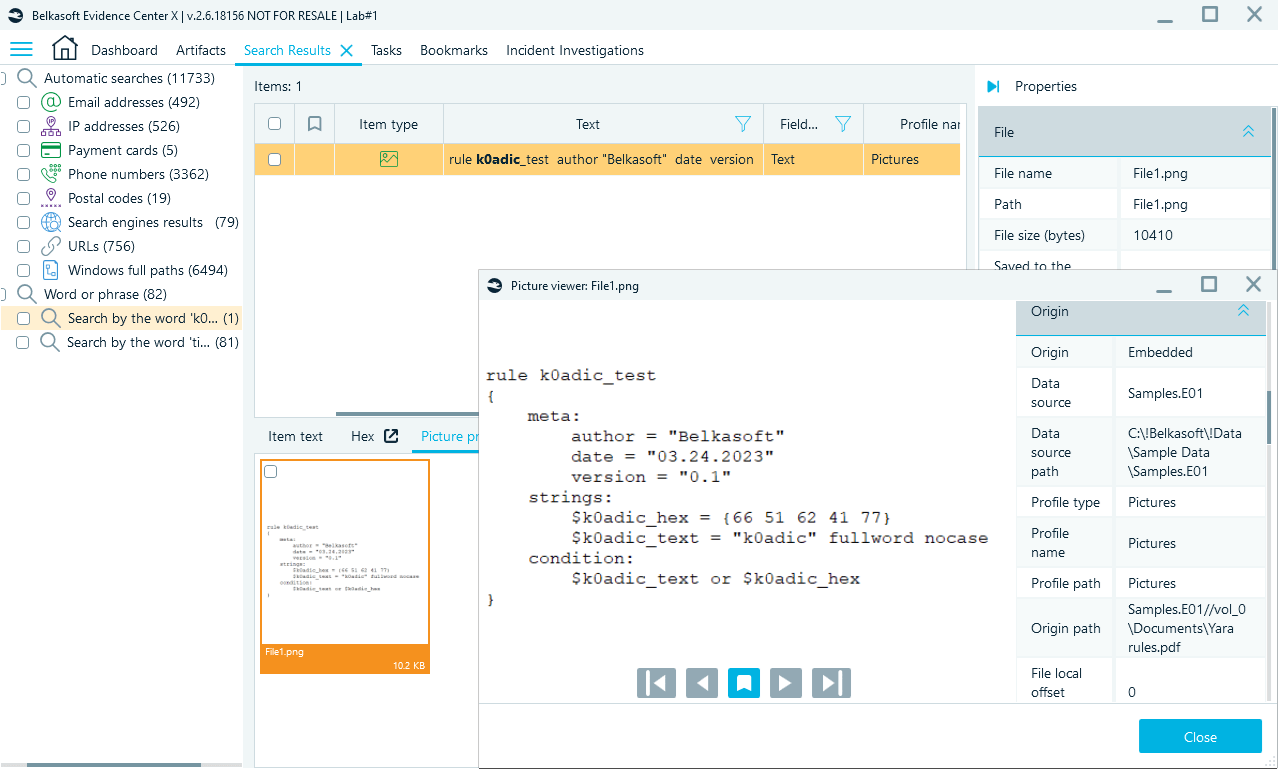
Text search results found in the image
Reviewing documents in Gallery view and Page previews
If text searches and image categorization do not yield what you are looking for, examining evidence file by file might be necessary. A user-friendly interface can speed up this process. Gallery view and Page previews in Belkasoft X provide a convenient toolset for navigating large volumes of documents.
Gallery view provides a thumbnail-based visualization of files, including images and videos. Instead of browsing through files in a grid view, you can see visual previews of items, which makes it easier to identify relevant content at a glance.
Page previews provide a snapshot or miniature of each page, giving a quick insight into the document content. For multi-page documents, page previews allow you to quickly flip through the content without fully opening the file.
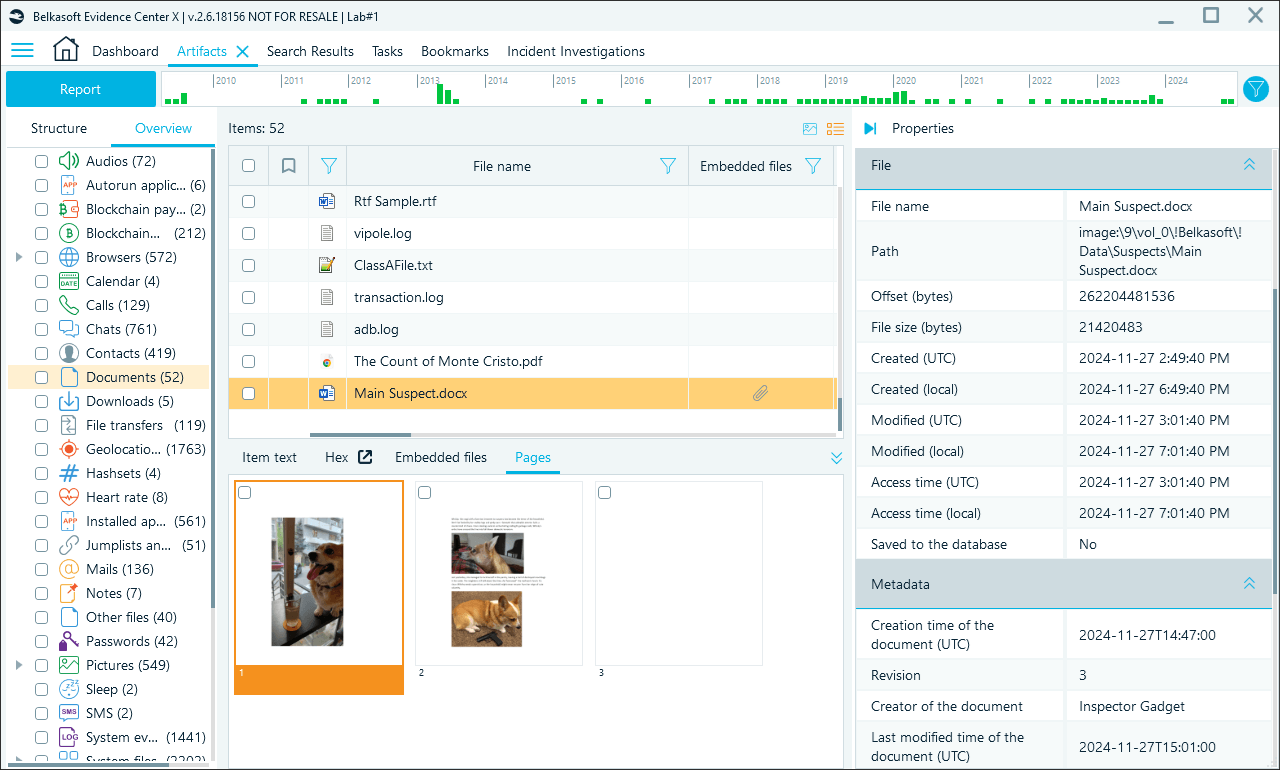
Page preview within the Documents profile gallery view in Belkasoft X
Conclusion
Document forensics is vital in modern corporate, criminal, and cybersecurity investigations, providing insights to uncover key evidence and reconstruct critical events. For optimal results, embedded media should be extracted and analyzed independently to reveal contextual clues and metadata, such as geotags or timestamps, essential for building accurate timelines and understanding document origins.
Belkasoft X streamlines these processes by offering powerful tools for metadata analysis, OCR, and embedded media examination. By automating and simplifying these tasks, Belkasoft X enables investigators to navigate complex datasets efficiently, ensuring that no evidence is overlooked and making investigations faster and more thorough.