Ins and Outs of Hashing and Hashset Analysis in Belkasoft X
Introduction
With ever-increasing device storage capacity, digital forensic cases and cyber incident response examinations are receiving more and more files to analyze. This data abundance leads to slowdowns in investigations and growing case backlogs. In this article, we will review hashes and hashset analysis as a means to mitigate the problem of growing volumes in a digital forensic or incident response (DFIR) case. We will use Belkasoft X software to illustrate the hashset analysis approach.
You will learn the mechanisms and standard practices of hashset analysis, which includes the following topics:
- What hash values are, and how they work
- Hashing algorithms and hash collisions
- Hashset analysis in digital forensics
- Public hashset databases
Additionally, we will look into the practical usage of hashsets with the Belkasoft X tool that provides the functionality to facilitate hashset analysis. We will demonstrate how to search for hashset matches on a data source and provide valuable tips on creating hashset databases.
What is a hash value?
Hashset analysis begins with generating hash values of evidence files with the help of a hash function. So let us first define what a "hash function" is.
In basic terms, a hash function is a function that takes an argument of any length and outputs a value of a fixed length. There are several other properties that make a function a "hash function". The first one derives from the function name. Outside the digital world, a hash is a dish made of chopped and mixed ingredients. The digital hash function "chops and mixes" data producing a fixed-size short value from an input of any size. This input can be anything—a password, a cryptocurrency transaction, any type of file, or even the full text of "The Lord of the Rings". The size of the output hash value is always the same.
The other essential properties of a hash function are:
- One-way calculation (inability to recover the input from the function output value)
- Calculation speed (it should be possible to calculate the value quickly)
- Low probability of collisions (we will look into collisions more closely below)
Like the hash dish can be cooked using various recipes, hash functions can use different hashing algorithms to calculate hash values. The most widespread hashing algorithms nowadays are MD5, SHA1, and SHA256. They differ in the hash calculation process and the output hash value length.

Figure 1: The hash value of the "Hello!" message generated with the MD5 hash algorithm
In digital technologies, hash values serve to identify data and validate its integrity, and here is why:
- A specific input always produces the same hash value if the same hashing algorithm is used. The hash value of a file stays the same regardless of the circumstances, so it can serve as its natural identifier.
- Even a slight change in the input data results in a different output hash. This way, a hash value of a file generated at two different times can prove that the file has not been altered in between them.
In DFIR, hash values are used to identify the files found during device investigations. Those can be illegal files like Child Sexual Abuse Material (CSAM) content and virus samples or, vice versa, standard operating system files that are surely legitimate.
In addition to file identification, DFIR uses hash values to ensure the chain of custody and preserve evidence integrity (see "Preserving chain of custody in digital forensics" for more details). Particularly, the device imaging process almost always includes the image file hash calculation to confirm its integrity. In Belkasoft X, you can specify one or multiple hash types calculation while acquiring a device:
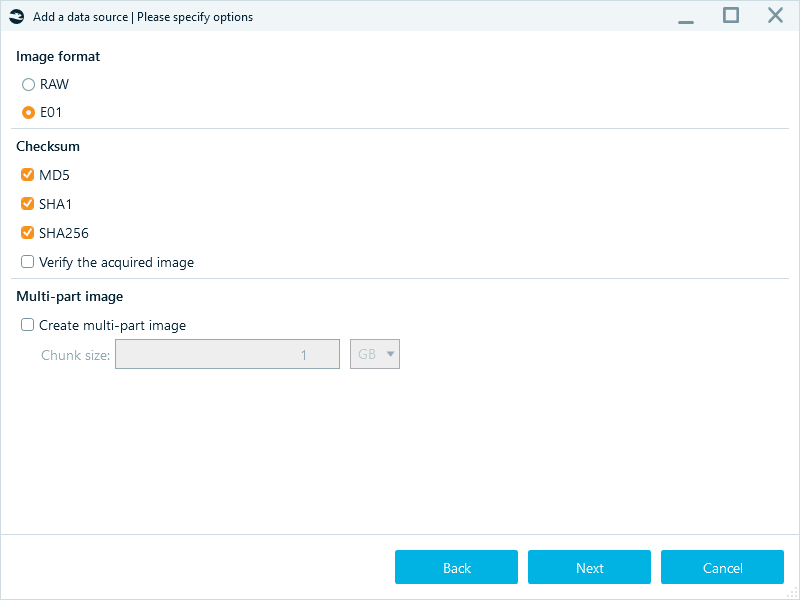
Figure 2: Selecting hashing algorithms for evidence integrity check during device acquisition in Belkasoft X
Considering that in digital forensics, hashing is predominantly used for files, it is important to note that hash values are typically calculated based on the file content and do not include metadata that may change as files travel between devices. If someone alters the file content, its hash value will also change, making it almost unmatchable for hashset analysis. However, techniques like fuzzy hashing and PhotoDNA can help identify modified files, such as resized or cropped photos.
Hash collisions
While a specific input always produces the same hash value, hashing algorithms may occasionally calculate the same hash value from different inputs. This event is known as a collision, and it may cause false matches during hashset analysis.
The MD5 and SHA1 algorithms tend to generate collisions more often because they produce shorter hash values, while SHA256 is less prone to those. However, MD5 and SHA1 are still suitable for file identification and integrity checks and are used a lot.
To avoid false positives when analyzing files with MD5- and SHA1-based hashsets, you can use these hash types in conjunction.
Hashsets databases
A forensic hashset database comprises collections of hash values associated with known files. These can be "blacklist" files containing illegal or malicious content or "whitelist" system files typically irrelevant to digital investigations. Since hash values are non-reversible, digital forensics specialists can freely store and share them even though the content of the files they represent may cause legal repercussions or harm to computers and networks. Another benefit of hash values is their size—they do not require much storage space compared to the files.
Using hashsets reduces the time and effort needed for manual inspection or traditional keyword-based searches. Instead of examining the content of the files, digital examiners can compare their hashes to a hashset database. While "blacklist" hashsets allow them to focus on specific files, "whitelist" hashsets help filter out legitimate files, reducing the volume of data to examine.
Law enforcement agencies create local hashset databases for internal use and can share them with other authorized entities. The most well-known global hashset databases include:
- National Software Reference Library (NSRL) provides the Reference Data Set (RDS) databases specialized in malicious data and non-RDS Child Abuse Image Database (CAID) sets
- ProjectVic focuses on CSAM materials
While NSRL hashsets are publicly available, ProjectVic hashsets are restricted to authorized organizations.
Hashset analysis with Belkasoft X
Belkasoft X enables you to run searches for matches in the following hashset database types:
- NSRL versions RDSv2 and RDSv3
- ProjectVic versions 1.3 and 2.0
- Text and CSV formats
You can initiate hashset analysis while adding a data source to your case:
- Launch the product, create a case, and add a new data source either from the Create case dialog or from the Actions menu on the case dashboard.
- After choosing the data source, navigate to the Hashes tab.
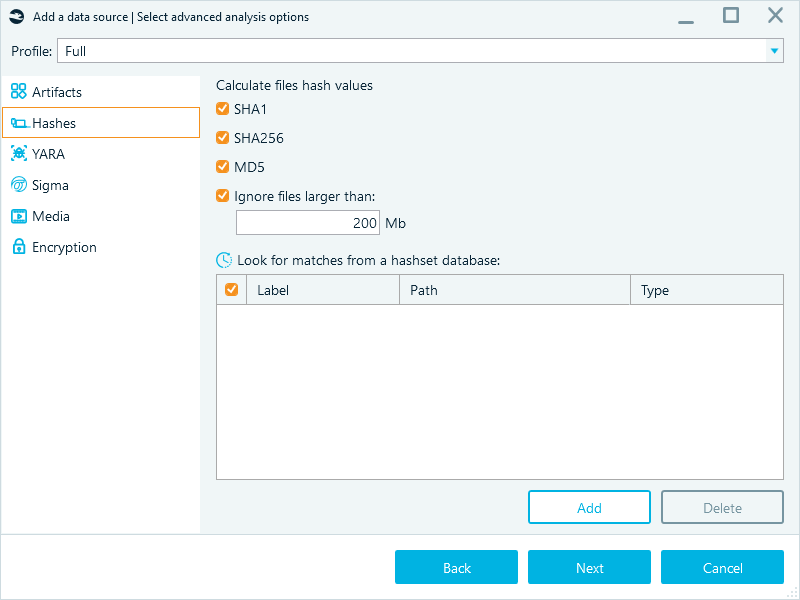
Figure 3: The Hashes tab used to define the hashset analysis options
- Select the hashing algorithms for calculating hashes of the files in the current data source. You can calculate all hash types or only choose the ones that are part of the hashset database you are going to provide for comparison.
- The Ignore files larger than checkbox is activated by default, with a limit of 200 Mb. This setting speeds up the analysis by ignoring huge files (for example, video files) that have a minimal probability of matching a hashset.
- Click Add and select the hashset database file to use in the analysis.
- Specify the Type of the selected hashset database. This value defines how Belkasoft X should treat the found hashes. The items matched with the Blacklist database will display in the Hashset node of the Artifacts → Overview tab, while the items matched with the Whitelist database will be hidden from the File System window.
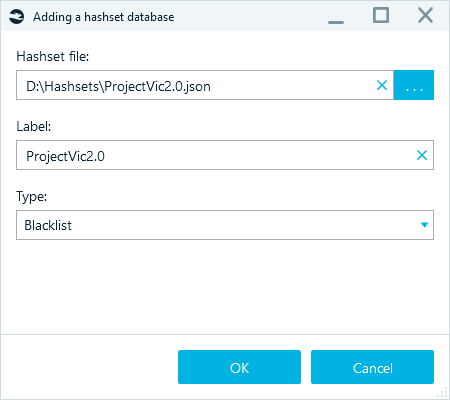
Figure 4: Specifying the hashset database details
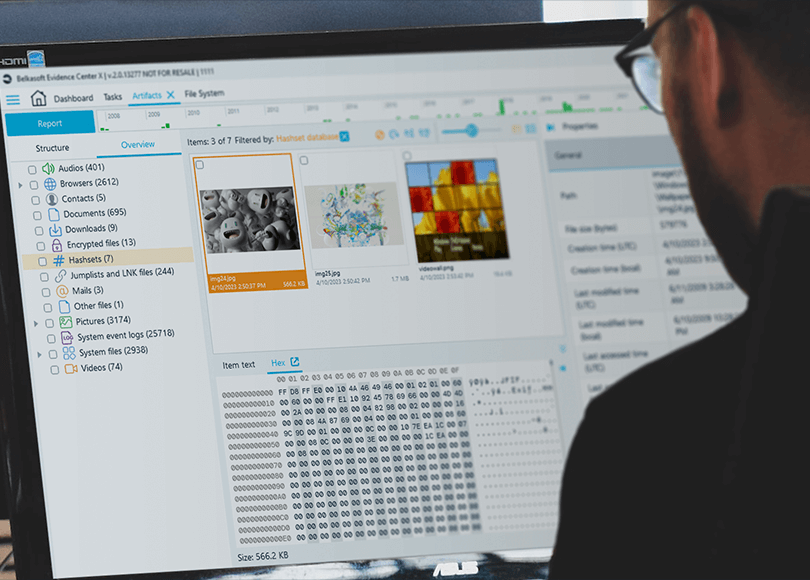
When you finish adding the data source, Belkasoft X calculates the hashes of the files and compares them to the ones in the provided hashset database. When the analysis is complete, you can find the matched "blacklist" items in the Artifacts → Overview tab:
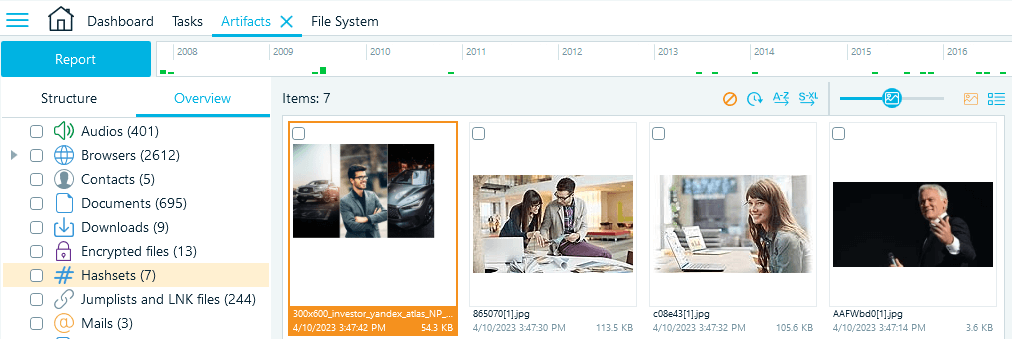
Figure 5: Belkasoft X displays matches under the Hashsets node
Hashset analysis is most often focused around media files, that is why Belkasoft X by default displays the items in the Gallery view to facilitate the examination. You can also switch to the text-based Grid view.
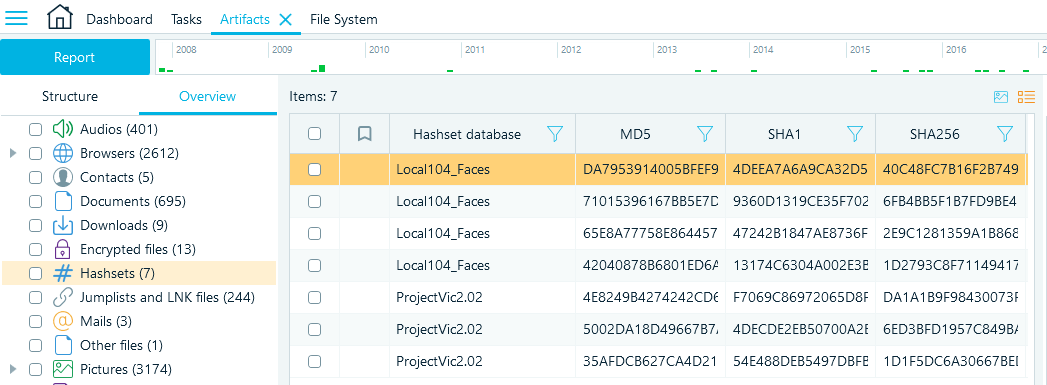
Figure 6: The Grid view of the Hashsets node
The filtering feature is helpful if you have too many matches and need to narrow down the search results. Click the Filter icon in a column header to select the filter options. For example, you can filter the results by a particular hashset database:
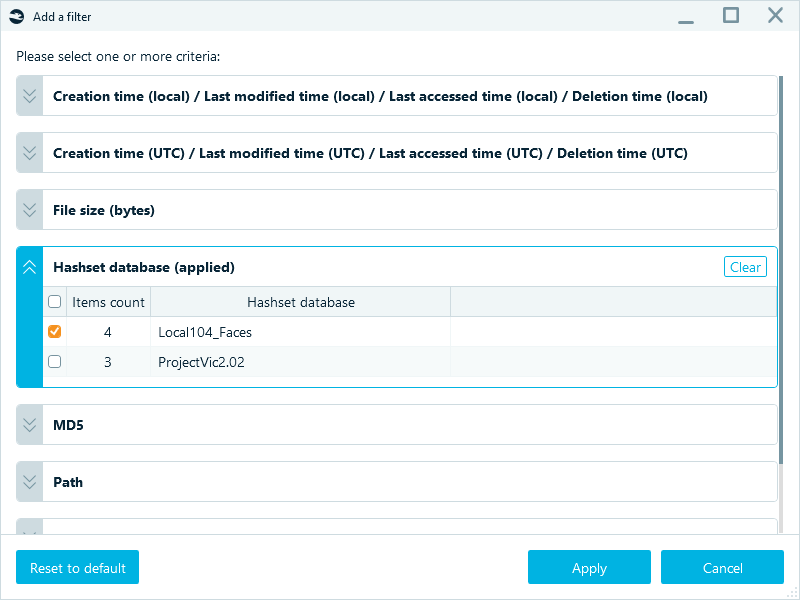
Figure 7: Filtering hash matches by the Local104_Faces hashset only
The Hashsets node also lets you bookmark matched items and include them in reports:
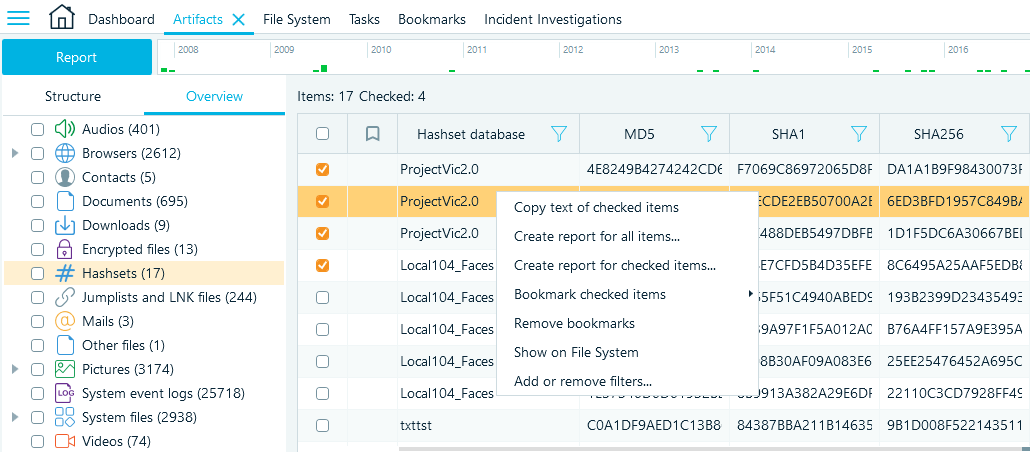
Figure 8: Hashset matches in the Grid view—context menu commands
If you need to find a matched file in the data source file system, select the Show on File System option, and Belkasoft X will locate and display it in the File System window.
Repeated hashset analysis
It may happen that you get a new or updated hashset, whether from your other case, your fellow investigator, or a new version of public hashsets. To avoid analyzing the same data sources for the second time, you can perform hashset analysis with the new or updated hashset by running it from the File System window.
Inside the File System window, right-click your data source, and select Run hashset analysis in the opened context menu:
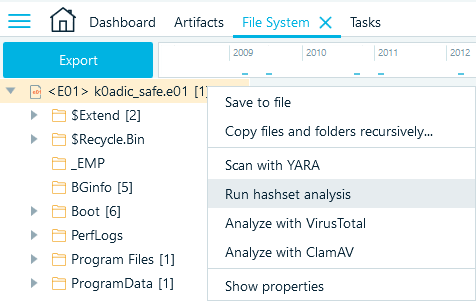
Figure 9: Running hashset analysis from the File System window
This feature is also helpful if you opted out of the hash analysis when adding the data source to the case.
Creating hashset databases with Belkasoft X
The reporting functionality in Belkasoft X provides a convenient way to export the hashes of the items from existing cases and create your own hashset databases. You can reuse exported hashsets within other cases, share them with fellow investigators, or use them with third-party software.
First, you need to calculate the hashes of the files in your data source if you have not done so before. You can do it either when adding a data source or from the File System window of an existing data source:
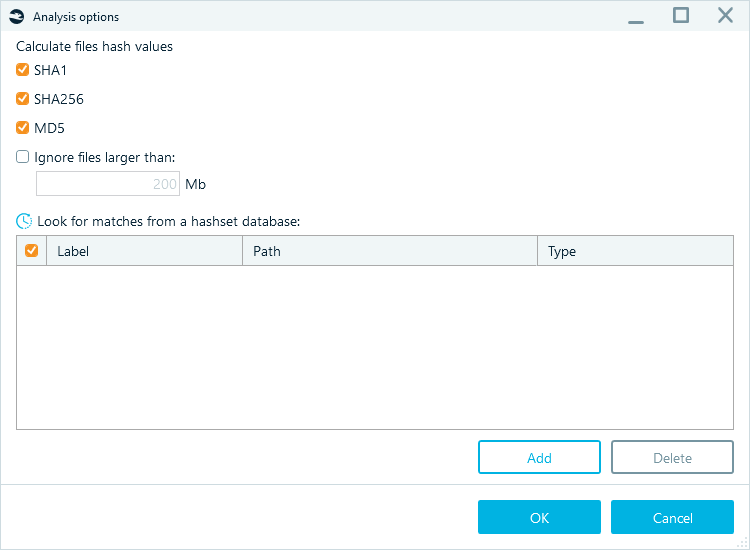
Figure 10: Calculating hashes for a data source
Next, select the items to export. Belkasoft X offers a few options for doing it:
- The most straightforward way is to go to the Artifacts window, select the checkboxes of the items whose hashes you want to export, right-click them, and select Create report for checked items:
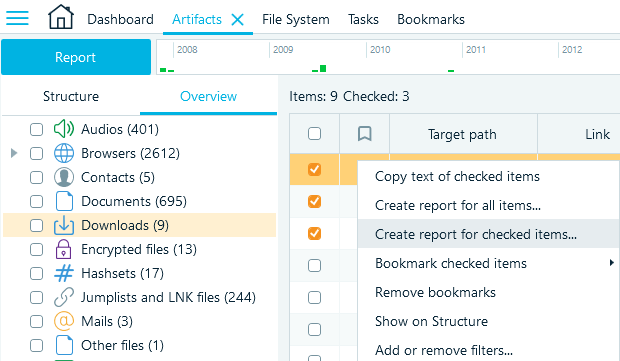
Figure 11: Selecting the items to export from the Artifacts window
- One more way is to export the data of all items of a node in the Artifacts → Overview tab. Right-click on a node and select Create report for checked profiles context menu item:
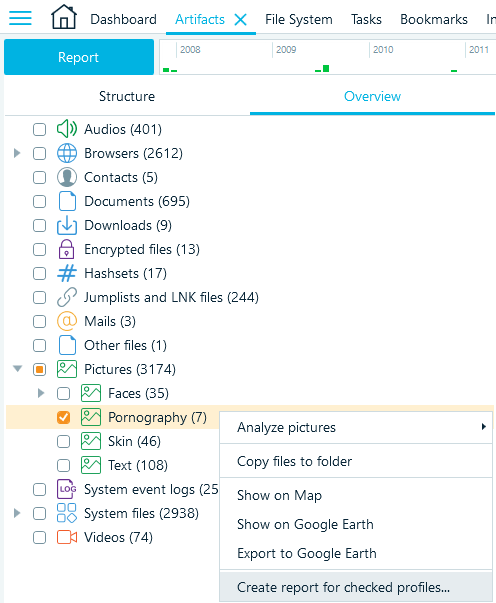
Figure 12: Selecting a profile to create a report
- Lastly, you can bookmark the items you want to export and assign them to categories. When you finish creating the categories, you can export all items under categories into reports from the Bookmarks window:
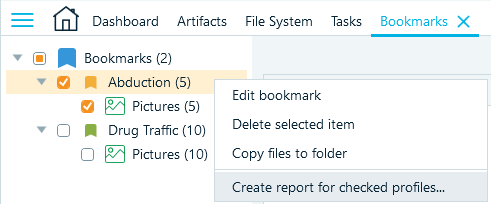
Figure 13: Creating a report from the Bookmarks window
After you select the files for exporting and select Create report..., your next steps depend on the format you select. Belkasoft X can help you export hashsets as text, CSV, Project Vic VICS format versions 1.3 and 2.0, and Semantics 21 (S21):
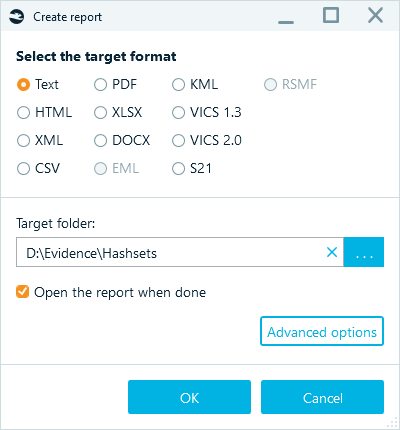
Figure 14: Selecting the report target format
Text and CSV
You can use the Text and CSV formats for storing hashset databases. To export the items into one of those formats:
- In the "Create report" window, select Text or CSV and click Advanced options.
- Select the Columns tab and clear the Selected columns pane using the << button.
- In the Available columns pane, select the hash property you want to include in the hashset and use the > button to select it for the report.
We recommend using SHA256 for hashset databases as it is less prone to collisions, which helps to avoid false positive results when running hashset analysis.
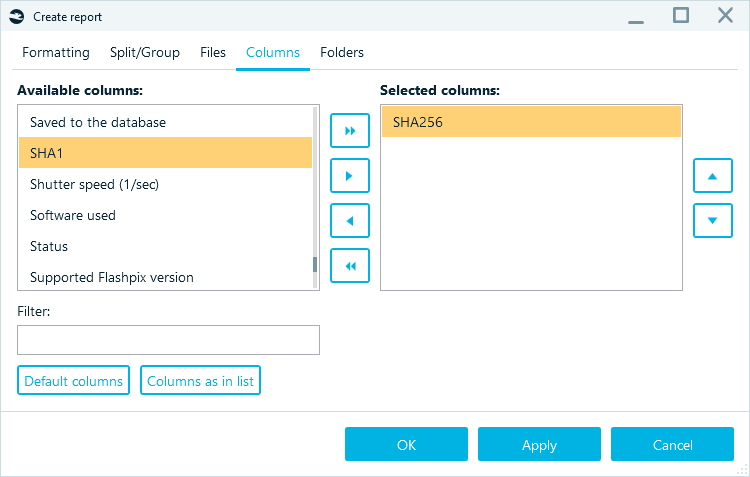
Figure 15: Defining the column to include in the report
As a result, Belkasoft X creates a report with just one column. A CSV file will look as follows:
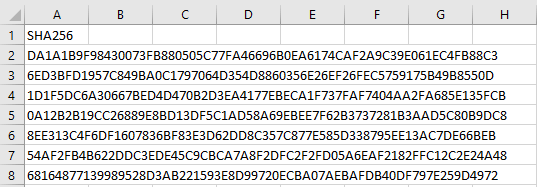
Figure 16: The CSV hashset report output
For the text format, the resulting hashset file may look similar to the following:
Figure 17: The Text hashset report output
ProjectVic
Another format supported by Belkasoft X is ProjectVic (VICS). You can use it to store your hashset databases, share them with other examiners and organizations, and contribute to the global databases.
To create a VICS hashset, select the VICS 1.3 or VICS 2.0 target report format.
In addition to hashsets, this type of report also exports the selected files so that you can import them into third-party tools, such as Griffeye Analyze DI Pro, used to automate image processing (see "Automation with Belkasoft: Orchestrating Belkasoft X and Griffeye DI Pro" for more details).
Semantics 21 (S21)
S21 is another format that exports both file details (including hashes) and the files. You can use it when working in the combined BelkaS21 software bundle or for importing into third-party tools like Amped FIVE.
To create such a report, select the S21 target format in the "Create report" window.
Conclusion
Hashing is an essential component of digital forensics and cyber incident response that works as a powerful means for identifying known files and ensuring the integrity of evidence. Hashset analysis enables investigators to effectively identify known files without opening and inspecting them manually. Such files typically include illegal or malicious content. Another possible application of hashsets is filtering out irrelevant files from the analysis process. By leveraging hashsets, investigators can streamline their investigations and focus their efforts on relevant and significant data.
Belkasoft X simplifies the hashset analysis process by enabling users to search for matches with popular hashset database formats, instantly review "blacklist" matches, filter matches by hashset database, preview matched picture files, and export the hashes of selected files to standard hashset formats.