
Introduction
In our previous article, "5 Bloopers of a Digital Forensic Investigator", we reviewed five of the most common mistakes made in the field of DFIR (Digital Forensics and Incident Response). The first article was a hit and our readers asked for a continuation.
Without any further delay we give you, "5 MORE Bloopers of a Digital Forensic Investigator".
Mistake #6: Failure to properly acquire RAM and lost encryption keys
Practically every modern digital device uses encryption. Encryption is everywhere. Modern mobile devices have it built-in by default—without a user explicitly choosing to switch it on. Computers, especially laptops can also have encryption enabled out-of-the-box, whether it is file system-based (APFS) or operating system-based (Bitlocker in Windows) encryption.
Because encryption is so pervasive and common it is most definitely a blooper to switch a running computer off to perform what is known as “dead-box acquisition. This was a general approach to data acquisition back in the ‘good old days’ before the encryption era. If you power down a modern encrypted device you will likely lose access to all the information you could have obtained and used to break that encryption.
Note: be sure to read the ACPO guidelines or similar documents discussing best practices, guidelines and rules for volatile memory acquisition.
When decryption is necessary, your best chance against encryption is to obtain a RAM dump from the active device. Data in volatile memory may contain decryption keys that could be the difference between success or failure (although we feel it is important to mention, that there is no guarantee that a RAM dump will produce device decryption keys!).
There are many nuances to an effective memory dump as a first step. This process alone has many pitfalls, one is a very wide-spread (not only all too common but frequently costly) mistake of using a forensic tool with a lot of capabilities and a large memory footprint. An example would be FTK Imager, an excellent tool for various types of acquisition, but a tool that requires far too much memory to be your tool of choice for RAM dumping. Its size is over 20 megabytes, while there are many other tools on the market that are hundreds of times smaller. Needless to say, the larger your tool of choice, the more user data is overwritten in memory when you run it, because the executable is loaded into memory to run.
Note: Here is a link to a free, light-weight RAM capture tool, which is under 100K in size: https://belkasoft.com/ram

Mistake #7: Performing a live browser session
This mistake sounds impossible, but nevertheless, every year we hear quite a few stories of this actually happening. And, it is a mistake that can happen to even more seasoned investigators, here is how:
- An inexperienced DFIR investigator might be tempted to perform live analysis on the device and try to get information only available from a browser executed by a logged in user. A dead-box image would mean that browser data might become encrypted. It is not a trivial task to decrypt such data (though possible: you can download a tool which can help with decryption by using this link)
- This mistake may also be caused by the fact that often the first person who gains access to a digital device, might not be a qualified digital investigator at all. Anyone who is not trained on how to properly seize devices, may have the temptation to quickly and recklessly acquire information from the live device, and cause irreparable harm to the admissibility of data in court later.
Attempting live analysis on a device using the suspect's account will likely cause severe problems in court as chain of custody cannot be assured.
Mistake #8: Attempts at brute-force decryption, which are likely to take over a billion years
Modern encryption has proven to be very robust. If a strong password is used, there are no known options to avoid time-consuming attempts to decrypt a file or a volume. This means that unlike algorithms used in the past, which allowed an examiner to test hundreds if not thousands of passwords per second, modern encryption requires multiple seconds per password attempted!
Running a full brute-force attack (in most cases) is not the smartest thing to do. Even with a high performance system, packed with memory and multiple graphics cards, sequential brute-force attempts can take billions of years to complete!
Hint: Check out our partner's masterpiece for password cracking: Passware Decryptum
By sequential brute-force we mean attempts to check passwords in sequential order from lowest to highest (e.g. a, b, c… aa, ab, ac and so on). It is easy to see how checking the vast volume of possible passwords one at a time, and multiplying each attempt by just one second per password, returns a terrifying result.
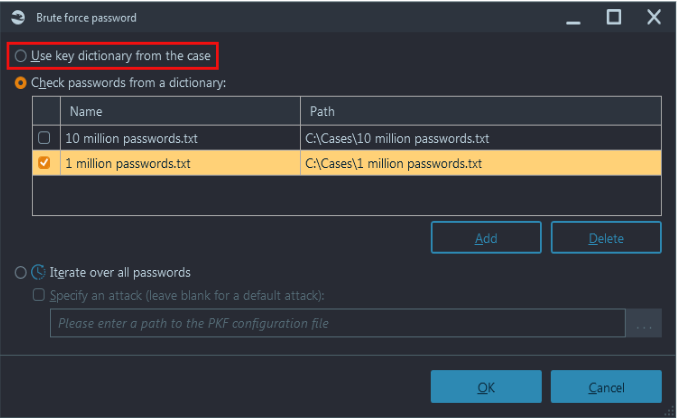
A better approach would be to try and apply some case-specific knowledge. If you already have some data extracted from a suspect's device (i.e. previously discussed memory dumps or hard drives), that knowledge can be used for decryption. Most people create passwords based on words in their vocabulary, words they use regularly (e.g. their kids names, past car models or cities they lived in). Combining such terms from the case and prioritizing attempts using those potential passwords significantly improve your chances for success.
Since most people reuse their passwords across multiple accounts, it is sometimes enough to find 'a weakest link'. An investigator may try to crack a password stored in the least secure place first, and then to apply that password to a more strongly encrypted item.
Some tools can help you create a user vocabulary as well. In our flagship DFIR product, Belkasoft X, this capability is called 'Create key dictionary'. This function is available from the product's Dashboard. Other tools, such as Passware Kit Forensic, can not only attempt to check every term from a key dictionary, but also create so-called mutations and combine different terms into one password. Though the number of mutations and combinations is naturally very large, it is still the best and most efficient approach identified for decryption to date.
Mistake #9: Confusing UTC and local time
There are many time zones all over the world (technically more than 24). Each and every time zone has its own local time: when it is 12pm in London, it is 7am in New York. Along with timezone conversion, some regions have time adjustments, such as daylight-saving time, when local time is moved one hour later or earlier depending upon the season. The switch to daylight savings is not necessarily synchronized between different countries, which introduces additional difficulties to understanding how time stamps saved in their local time correlate to each other.
The date and time storage standard is Coordinated Universal Time (UTC time). This means most applications and systems are storing timestamps in UTC. However, this may introduce inconveniences and confusion to regular users, who naturally prefer seeing their local time. This is why applications may opt to store timestamps in local time, which is set on each individual user's device.
Now, since the volume of data in today's cases can be overwhelming, it is easy to make the mistake of confusing UTC and local time, stored by different applications. If you do not convert all times to UTC (or local), you may encounter a situation where the order of chat messages are reversed. This occurs if one chat application stores its time in UTC, while the other uses local time.
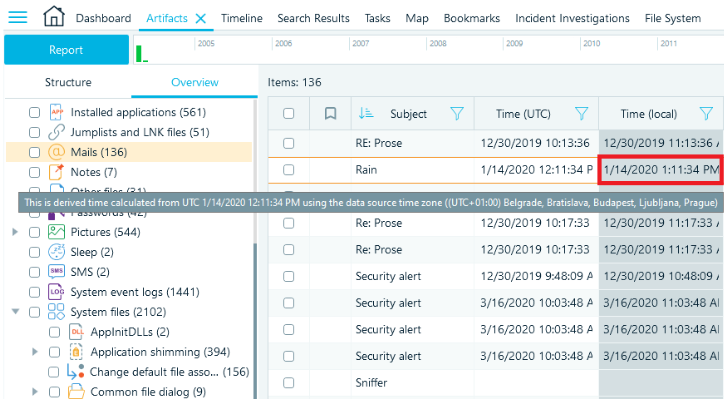
Your forensic tool may further this confusion for a variety of artifacts if the timestamps are not accurately converted. The issue deepens if you have several data sources from different time zones (e.g. a computer hard drive from Arizona and an iPhone from Washington DC). The forensic tool you choose must allow you to specify different time zones for different devices in your case in order to avoid any timestamp confusion. Not specifying a time zone offset in such a case is another facet to the same mistake.
Note: Belkasoft X allows an investigator to set a time zone for the case as well as for every data source. From a column name, you always know whether UTC or local time was used to store a timestamp. The other column, which contains derived time, calculated by the product, will have another background color and a hint, shown when hovering on the column cell. Thanks to automatic time recalculation, Belkasoft X correctly merges different events having different time offsets on its Timeline tab.
Mistake #10: Bricking a mobile device in evidence
The more mobile devices evolve, the harder it is to capture data from them. Physical images, available when the first smartphone was introduced, are no longer viable due to built-in encryption features. And, standard backups offer a very limited amount of data. This is why most modern approaches to acquire smart device data are based on known vulnerabilities and subsequent exploits.
A common mistake would be to blindly use one of these exploits without first testing it on a donor phone. Any inaccuracy or error in steps (e.g. an incorrect time delay or a slightly different SoC (System on a Chip) model than what is supported by an exploit)—and you can inadvertently brick a device. Losing evidence in this fashion is not just frustrating, it can be ruinous to your case if the device is a critical source of evidence. Best practices involve a careful test run of any acquisition method that utilizes a device exploit by using a similar, or preferably, the exact model device.
It is worth mentioning that sometimes even devices that have the absolute same model and the same SoC inside, may behave differently. Sadly, this means that a successful test-run, even on the same device, is not a 100% guarantee that the exploit is safe for that specific device. However, it obviously increases your chance for success and is better than not testing at all.
As the famous essay from Alexander Pope tells us, “to err is human. With the proliferation and advancement of technology and the ever increasing complexity of the forensics world at large, this expression has never been more true for the DFIR community. Our hope is that by sharing some of our common mistakes we limit the chance of making a crucial or costly mistake in the future. To advance our field and help new examiners improve we all need to work together and share some of our biggest bloopers, blunders and mistakes. It is important that we all work together and never stop learning from each other.
You can help improve and expand this article by sending your ideas, blunders, bloopers (and how to avoid or mitigate them) to sales@belkasoft.com.